Plot dot plot#
This notebook will help you generate “Prism-style” dot plots in Python, inspect the distribution of your data, and run two-sample statistics.
Step 1. Import Data#
For this notebook, we can either import our data from a CSV file, or by manually entering the values.
If you’d like to import your data from a CSV file, you will need to follow the instructions for uploading data to Colab on the home page. If you are using this option, comment out the lines of code under Option 2.
Task:
Change
data_1anddata_2to be your two groups of data. Make sure you leave these as lists, with brackets on each end, and each data point separated by a comma.Optional: Rename
Condition_1andCondition_2. Make sure you keep these in single quotes, so Python recognizes them as a string!
# Option 1: Import a CSV file as a Pandas dataframe
import pandas as pd
#filename = ...
#data = pd.read_csv(filename)
# Option 2: Import your data as two lists and generate a dataframe from it
data_1 = [1,3,3,2,1,2,4,2,5]
data_2 = [3,4,5,3,2,6,7,8,3]
data = pd.DataFrame(data={'Condition_1':data_1,'Condition_2':data_2})
# Show the data
data
| Condition_1 | Condition_2 | |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 3 | 4 |
| 2 | 3 | 5 |
| 3 | 2 | 3 |
| 4 | 1 | 2 |
| 5 | 2 | 6 |
| 6 | 4 | 7 |
| 7 | 2 | 8 |
| 8 | 5 | 3 |
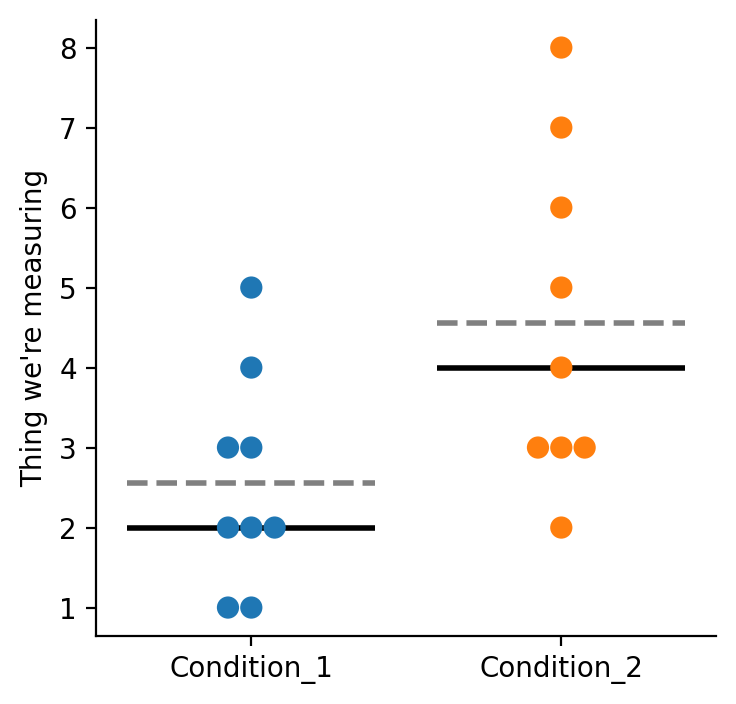
Step 2. Plot Data#
Below, we’ll use a seaborn plotting function called swarmplot to plot each of our data points.
Notes#
This will draw a dotted gray line for the mean, and a solid black line for the median.
Change the
plt.ylabelline to add your own label.
# Import needed packages
import seaborn as sns
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
# Set up the plot
fig,ax = plt.subplots(1,1,figsize=(4,4))
# plot the mean line
sns.boxplot(data=data, showmeans=True,meanline=True,
meanprops={'color': 'gray', 'ls': '--', 'lw': 2},
medianprops={'visible': True,'color': 'black', 'ls': '-', 'lw': 2},
whiskerprops={'visible': False},
showfliers=False,showbox=False,showcaps=False)
# plot individual data points
sns.swarmplot(data=data,s=8)
plt.ylabel('Thing we\'re measuring')
# Make the axes look nice!
ax.spines[['right', 'top']].set_visible(False)
plt.show()
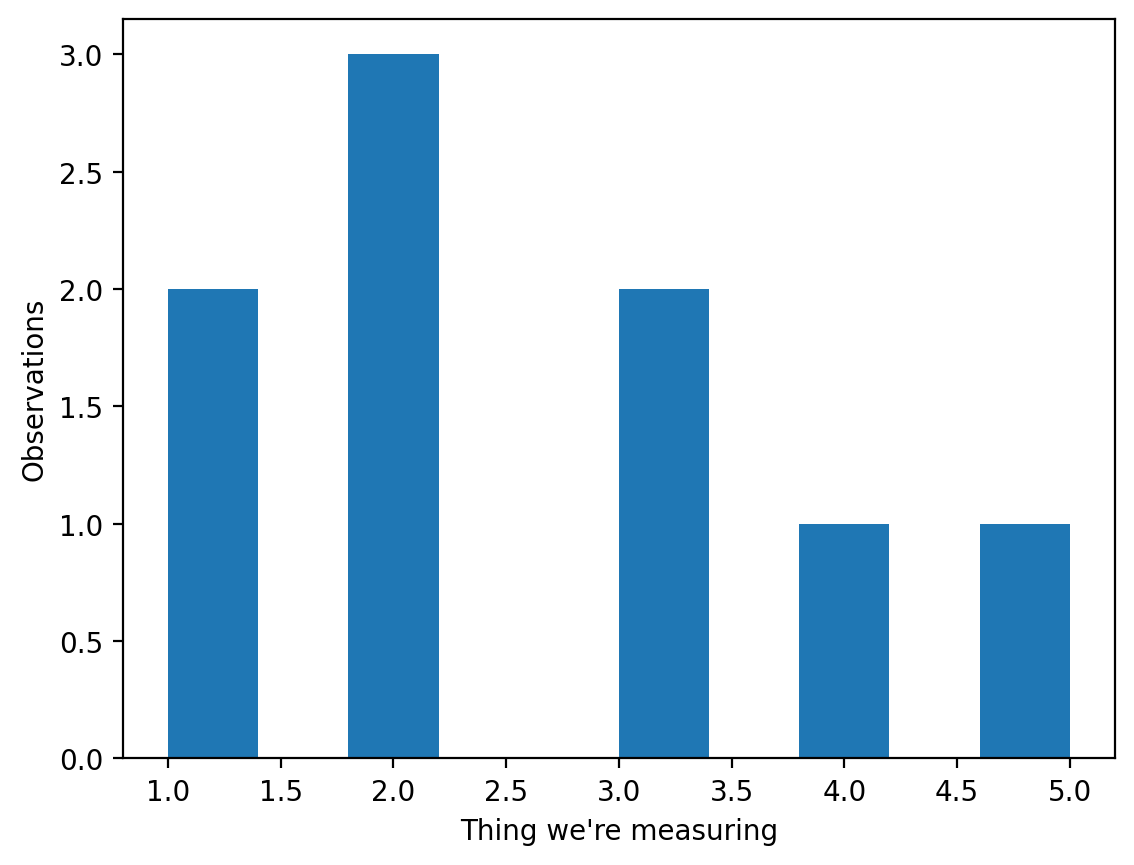
Step 3. Check to see how skewed the data is#
Before we run any hypothesis tests, we need to know if our data is skewed or not. To test for skewness, we can use stats.skewtest to test. This method implements the D’Agostino-Pearson skewness test, one of many different tests that can be used to check the normality of a distribution. If the skew test gives us a p-value of less than 0.05, the population is skewed.
Note:
skewtestrequires at least 8 samples. If your group has fewer than 8 data points, skip to the Kolmogorov-Smirnov test option below instead.
Task: Run the cell below, but then change the
sampletodata_2(or create a separate cell fordata_2) to test your second group of data points.
from scipy import stats
sample = data_1 # Choose which data to use
stat,pvalue = stats.skewtest(sample) # Run the skew test
# Print the p value of the skew test up to 30 decimal points
print('The skewtest p-value is ' + '%.30f' % pvalue)
plt.hist(sample) # Create a histogram
plt.ylabel('Observations')
plt.xlabel('Thing we\'re measuring')
plt.show()
The skewtest p-value is 0.346991576561619385898893597187
Option B: Kolmogorov-Smirnov test (for small samples)#
The Kolmogorov-Smirnov (KS) test compares your sample against a theoretical normal distribution and works for any sample size. If the KS test gives a p-value of less than 0.05, the data significantly deviates from normal.
Task: Change
sampletodata_1ordata_2and run the cell.
import numpy as np
sample = data_1 # Choose which data to use
# Kolmogorov-Smirnov test for normality
# Tests whether the sample could have come from a normal distribution.
# Works for any sample size (including n < 8).
# If p < 0.05, the data significantly deviates from normal (i.e., it is skewed).
stat, pvalue = stats.kstest(sample, 'norm',
args=(np.mean(sample), np.std(sample)))
print('KS statistic: ' + str(round(stat, 4)))
print('KS p-value: ' + '%.30f' % pvalue)
plt.hist(sample)
plt.ylabel('Observations')
plt.xlabel('Thing we\'re measuring')
plt.show()
KS statistic: 0.2263
KS p-value: 0.666861007096217206502331009688
Step 4. Run two-sample statistics#
Inferential statistics generalize from observed data to the world at large#
Most often, the goal of our hypothesis testing is to test whether or not two distributions are different, or if a distribution has a different mean than the underlying population distribution.
The SciPy stats package has many hypothesis testing tools. For many simple cases in biology or neuroscience research, we’d like to test whether two or more distributions are different from eachother.
If we know our distributions are normal (they’re generated from a normal distribution!) we can use parametric statistics to test our hypothesis. To test for differences between normal populations, we can use the independent t-test in our stats package: stats.ttest_ind().
If we had paired samples, we would use a dependent t-test as seen here.
If one of our populations is skewed, however, we cannot use a t-test. A t-test assumes that the populations are normally distributed. For skewed populations, we can use either the Mann-Whitney U (for independent samples, stats.mannwhitneyu()) or the Wilcoxon Signed Rank Test (for dependent/paired samples,stats.wilcoxon()).
Below, there is sample code to run three different statistical tests. You should use only the one that is most appropriate for your data by uncommenting that line.
print(stats.ttest_ind(data_1,data_2)) # to run an independent t-test
# print(stats.ttest_rel(data_1,data_2)) # to run an dependent t-test
# print(stats.mannwhitneyu(data_1,_2)) # to run a mannwhitneyu
# print(stats.wilcoxon(data_1,data_2)) # to run a wilcoxon signed rank test
TtestResult(statistic=np.float64(-2.4382276613229465), pvalue=np.float64(0.026796307428331737), df=np.float64(16.0))
That’s it for this notebook! You can adapt this code for lots of different projects (including your final project!).